
openCVを使い画像読み込み、fftで周波数データに変換。その後逆変換で元の画像に戻すテスト。
入力に使用する画像は↓。サイズは360×240。

まず画像入力、グレースケールで取り込む。
|
1 2 3 4 5 6 7 8 9 10 |
########### # code 1 ########### import cv2 from PIL import Image image = cv2.imread("mt_fuji.jpg", cv2.IMREAD_GRAYSCALE) cv2.imshow("original",image) cv2.waitKey(0) cv2.destroyWindow() |
実行すると元の画像がグレースケールで表示される。
imreadは引数2つ、1つ目は読み込みファイル、2つ目は読み込みオプションで以下3つ(1,0,-1でも指定可)。
cv2.IMREAD_COLOR (or 1)
cv2.IMREAD_GRAYSCALE (or 0)
cv2.IMREAD_UNCHANGED (or -1)
続けてFFT実施
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
########### # code 2 ########### import cv2 import numpy as np from PIL import Image image = cv2.imread("mt_fuji.jpg", cv2.IMREAD_GRAYSCALE) #cv2.imshow("original",image) #cv2.waitKey(0) #cv2.destroyWindow() fimage = np.fft.fft2(image) print fimage print fimage.shape |
np.fft.fft2()は2次元FFT。
実行結果が下記。入力が360×240画像だったので、360×240のnumpy arrayで返ってくる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[[ 1.20523050e+07 +0. j -3.67019062e+05 +764482.77644721j 8.97803335e+04 +528353.446206 j ... -8.56635235e+04 -151789.8195801 j 8.97803335e+04 -528353.446206 j -3.67019062e+05 -764482.77644721j] [-5.06881547e+05-1884930.25115523j -4.50139049e+04 -190712.10861819j -1.76090294e+05 -185634.30113876j ... 8.13464047e+04 +33421.45807695j 1.54174557e+05 +151124.32767313j 2.22512389e+05 +112510.91249437j] [-2.70716797e+05 +598066.58169905j 2.74010196e+05 +76140.89477773j 3.81093895e+04 -142669.2043982 j ... 7.45069646e+04 -13227.88422994j 2.39614427e+03 -107962.49955725j -1.21014694e+05 +16070.44342708j] ... [-4.93325081e+05+1019497.68318583j 1.10749640e+05 -185659.62071232j -2.02180759e+04 -244150.48215119j ... -7.68268395e+03 +7667.31543078j 1.36815674e+05 -2094.526859 j 4.18478921e+04 -76427.43943856j] [-2.70716797e+05 -598066.58169905j -1.21014694e+05 -16070.44342708j 2.39614427e+03 +107962.49955725j ... -5.75415408e+02 +50912.11759434j 3.81093895e+04 +142669.2043982 j 2.74010196e+05 -76140.89477773j] [-5.06881547e+05+1884930.25115523j 2.22512389e+05 -112510.91249437j 1.54174557e+05 -151124.32767313j ... -4.22761652e+04 +70475.447572 j -1.76090294e+05 +185634.30113877j -4.50139049e+04 +190712.10861819j]] (240, 360) |
変換結果をパワースペクトルで確認してみる。確認に使用したコードが下記。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
########### # code 3 ########### import cv2 import numpy as np import matplotlib.pyplot as plt from PIL import Image image = cv2.imread("mt_fuji.jpg", cv2.IMREAD_GRAYSCALE) #cv2.imshow("original",image) #cv2.waitKey(0) #cv2.destroyWindow() fimage = np.fft.fft2(image) #print fimage #print fimage.shape # Replace quadrant # 1st <-> 3rd, 2nd <-> 4th fimg = np.fft.fftshift(fimage) # Power spectrum calculation mag = 20*np.log(np.abs(fimg)) plt.subplot(121) plt.imshow(image,cmap = 'gray') plt.subplot(122) plt.imshow(mag,cmap = 'gray') plt.show() |
実行結果下記
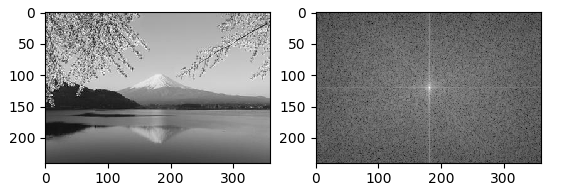
最後に逆変換で元の画像に戻すコード。注意として変換後の結果には複素数成分が含まれているので、実部を取り出す処理が必要。またグレースケールで表示するために0-255階調への値調整が必要になる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
########### # code 4 ########### import cv2 import numpy as np import matplotlib.pyplot as plt from PIL import Image image = cv2.imread("mt_fuji.jpg", cv2.IMREAD_GRAYSCALE) #cv2.imshow("original",image) #cv2.waitKey(0) #cv2.destroyWindow() fimage = np.fft.fft2(image) #print fimage #print fimage.shape ifimage = np.fft.ifft2(fimage) # Extract real part ifimage = ifimage.real # Convert to 255 tones for gray scale ifimage = np.uint8(ifimage) cv2.imshow("fft and ifft",ifimage) cv2.waitKey(0) cv2.destroyWindow() |
実行結果が下記グレースケールでもとの画像に戻ってきた。

Read images using openCV, convert to frequency data with fft. And then back to the original image with reverse transformation.
Code 1 is reading image by gray scale.
Code 2 is 2D fft by numpy. Frequency distribution is returned.
Code 3 is checking Power spectrum.
Code 4 is invers Fourie by numpy.