HOGDescriptorは被探索画像を64 * 128 などの単位でスキャンし、8 * 8などのピクセルを移動させてHOG特徴量の抽出を行う。HOG特徴量は領域内の勾配方向ごとの勾配強度を計算してそれをヒストグラムにしたものらしい。画像中の輝度変化を抽出していることになる。
SVMは入力が正解か不正解を分類する分類器。大量のデータとラベルの組から正解ラベルのデータ、不正解ラベルのデータを学習し正解と不正解の境界線を引く。
opencvにはすでに学習済みの人識別器が同梱されており、これを使って人の検出を行ってみる。
■入力画像

■サンプルコード
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import cv2 im = cv2.imread("people.jpg") # Calculation of HoG feature quantity hog = cv2.HOGDescriptor() #Create Human Identifier with HoG feature quantity + SVM hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector()) #widStride :Window movement amount #padding :Extended range around the input image #scale :scale hogParams = {'winStride': (8, 8), 'padding': (32, 32), 'scale': 1.05} #Detected person coordinate by the created identifier device human, r = hog.detectMultiScale(im, **hogParams) #Surround a person's area with a red rectangle for (x, y, w, h) in human: cv2.rectangle(im, (x, y),(x+w, y+h),(0,50,255), 3) #show image cv2.imshow("results human detect by def detector",im) cv2.waitKey(0) |
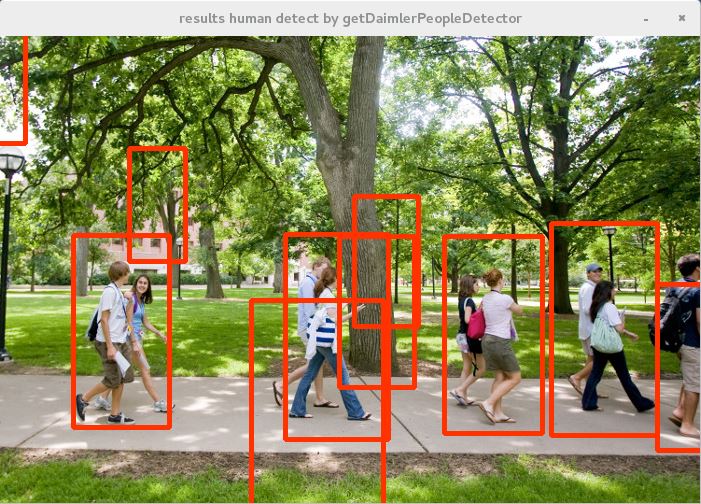
■実行結果
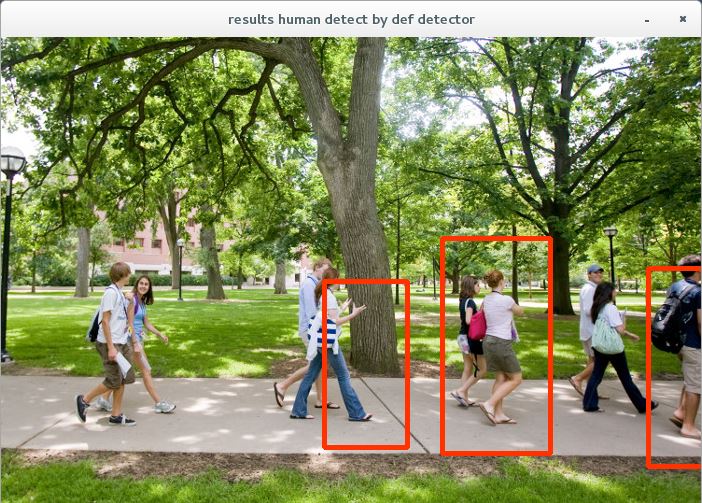
検出漏れはあるが、とりあえず機能はしている様子。opencvの人認識器には今回試したgetDefaultPeopleDetector以外にgetDaimlerPeopleDetectorという認識器が同梱されている。これについては次回以降で実験してみる。
HOG Descriptor scans the search image by units such as 64 x 128, moves pixels such as 8 x 8, and extracts the HOG feature amount. It seems that the HOG feature quantity is calculated by calculating the gradient strength for each gradient direction in the region and making it a histogram. The luminance change in the image is extracted.
SVM is a classifier that classifies incorrect answers or incorrect answers. Learn the data of the correct label and the data of the incorrect label from the large amount of data and the set of labels and draw the boundary line between the correct answer and incorrect answer.
Opencv is already shipped with a learned person identifier, and try to detect people using it.
Results:Detection is insufficient, but it seems that it is functioning for the time being. In this time, we tried getDefaultPeopleDetector on human recognition device of opencv and recognition device called getDaimlerPeopleDetector is bundled. I will experiment about this next time.